스케일 큐브 (크리스 리차드슨)
This a translation of an article Scale Cube originally written and copyrighted by Chris Richardson.
이글은 Chris Richardson가 작성하였으며, 저작권을 가지고 있는 Scale Cube 글의 번역본입니다.
The Art of Scalability 책에서는 매우 유용한 세 가지 관점의 규모확장성(Scalability) 모델인 스케일 큐브(scale cube) 를 설명한다.
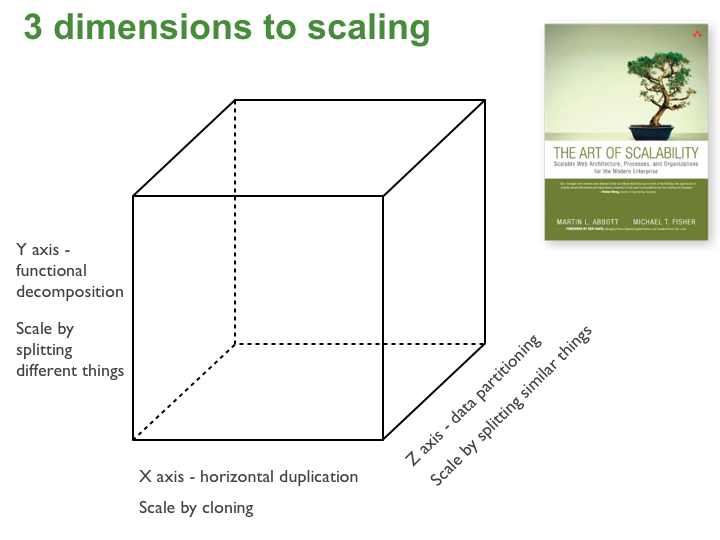
이 모델에서는 로드 발란서 뒤에 복제본을 실행해 애플리케이션의 확장성을 확보하는 방법을 X축 확장(X-axis scaling)이라 부른다. 다른 두 종류의 확장 방법으로는 Y축과 Z축 확장이 있다. 마이크로서비스 아키텍처는 Y축 확장 애플리케이션을 말하지만 X축과 Z축 확장 또한 살펴보자.
X축 확장(X-axis scailing)
X축 확장은 로드 발란서 뒤에 다수의 애플리케이션 복제본을 실행해 구성한다. N개의 복제본이 있다면 각 복제본은 1/N 부하를 처리한다. 이것은 매우 단순하며, 애플리케이션의 확장성을 확보하는 일반적인 방법으로 사용된다.
이 접근방법의 한 가지 단점은 각 복제본이 모든 데이터에 접근할 가능성이 있기 때문에 사실상 캐시가 더 많은 메모리를 필요로 한 다는 점이다. 이 접근방법을 사용할 때의 또 다른 문제로는 개발과 애플리케이션의 복잡성이 증가하는 문제를 막을 수 없다는 점이다.
Y축 확장(Y-axis scailing)
애플리케이션의 동일한 복제본 다수를 실행해서 구성하는 X축, Z축과는 다르게 Y축 확장은 애플리케이션을 여러 다른 서비스로 분할한다. 각 서비스는 엄밀하게 하나, 또는 그 이상의 관련된 기능의 책임을 진다. 애플리케이션을 서비스로 분해하기 위한 각기 다른 두 가지 방법이 있다. 첫 번째 접근 방법은 동사를 기준으로 사용해 분해해 체크아웃처럼 하나의 유즈케이스를 구현하는 서비스를 정의하는 것이다. 다른 옵션으로는 명사로 애플리케이션을 분해하고 고객 관리처럼 하나의 엔티티에 관련된 모든 연산을 책임지는 서비스를 만드는 방법이 있다. 하나의 애플리케이션에서 동사를 기준으로 하는 분해방법과 명사를 기준으로 분해하는 방법을 조합해서 사용할 수도 있다.
Z축 확장(Z-axis scailing)
Z축 스켈일링을 사용하면 각 서버는 동일한 코드의 복제본으로 실행한다. 이 점에서는 X축 확장과 비슷하다. 가장 큰 차이점은 각 서버가 데이터의 일부만을 책임지는 점이다. 시스템의 컴포넌트는 각 요청을 적절한 서버로 전달하는(routing) 책임이 있다. 일반적으로 사용하는 경로선택 기준은 접근하려는 엔티티의 주키와 같은 요청의 속성이다. 또 다른 일반적인 경로선택 기준으로 고객 유형이 있다. 예를 들어, 애플리케이션을 무료로 사용하는 고객보다 더 높은 SLA를 사용하는 고객이 보내는 요청은 더 큰 용량을 처리하는 다른 서버군으로 보냄으로써 지불 서비스를 제공할 수 있다.
Z축 분해는 일반적으로 데이터베이스의 확장성을 확보할 때 사용한다. 데이터는 각 레코드의 속성에 따라 각 서버군으로 분할된다(shard로 알려짐). 일례로 RESTAURANT 테이블의 주키를 사용해 두 개의 다른 데이터베이스 서버로 분해한다. X축 복제는 replicas/slaves로 하나, 또는 그 이상의 서버를 배포함으써 각 파티션에 적용할 수 있다는 걸 기억하자. Z축 확장은 애플리케이션에도 적용할 수 있다. 이 예제에서 각 검색 서비스는 여러 파티션으로 구성된다. 라우터는 각 콘텐츠 항목을 적절한 파티션으로 보내서 인덱싱을 하고, 저장한다. 쿼리 어그리게이터(query aggregator)는 각 쿼리를 모든 파티션으로 보내고 각 파티션의 결과를 조합한다.
Z축 확장은 여러 장점이 있다.
- 각 서버는 일부 데이터만을 다룬다.
- 이는 캐시 활용을 높이고, 메모리 사용과 I/O 트랙픽을 줄인다.
- 일반적으로 요청을 다수의 서버로 분산하기 때문에 트랜잭션의 확장성을 또한 개선한다.
- 또한 Z축 확장은 접근하는 데이터의 일부에서만 장애(failure)가 일어나기 때문에 장애고립(fault isolation , 역-더 좋은 표현은?)을 향상시킨다.
Z축 스케일잉은 몇 가지 단점도 있다.
- 첫 번째 단점은 애플리케이션 복잡도를 높인다는 것이다.
- 파티셔닝 스키마를 구현해야 하며, 데이터를 다시 파티셩닝이라도 해야 하는 경우에 특히나 힘들어질 수 있다.
Z축 확장의 또 다른 단점으로는 개발과 애플리케이션의 복잡도 향상 문제를 해결하지 못한다는 점이다. 이 문제를 해결하기 위해서는 Y축 확장을 적용해야 한다.